
💡 This post also exists as a video for those who prefer watching over reading.
Developers don’t need more magic, we need reliable systems. Deep research isn’t a single prompt—it’s a workflow: break a question down, fetch sources, extract signal from noise, find gaps, and synthesize. This is typically a good case for multi‑agent systems over single agent ones.
A single, do‑everything agent tends to hesitate, overthink tool choices, and blur responsibilities as we've previously documented. Splitting the work across small, specialized agents keeps each one sharp and independently testable. If the summarizer misbehaves, the rest of the pipeline keeps running; if the retriever needs tuning, you fix that node without touching the rest. Most importantly, each agent speaks a predictable contract so the next stage isn’t guessing what it will get.
The 5‑agent deep‑research flow
Our system starts with a Research Planner agent that takes the user’s question and breaks it into 3–7 crisp, self‑contained sub‑questions. When it's finished, it hands and those to a Source Finder agent equipped with a web search tool; for each sub‑question it returns a small set of high‑signal links with titles, URLs, summaries, and content (or a placeholder if the site blocks scraping).
Those are then fed to a Summarization agent that extracts only the facts relevant to each sub‑question. A Reviewer agent scans the overall coverage, flags gaps, mechanisms, counter‑views, or unclear assumptions, and proposes new sub‑questions if needed. Finally, a Professional Research Writer agent synthesizes a structured report that actually reads well. You can even run the final writer on a bigger model while keeping the earlier nodes lean to manage costs.
This is where Langflow particularly shines, allowing us to mix and cherry pick models per node—small for planning, tool‑friendly for retrieval, bigger for synthesis—without contorting your code and while maintaining a clear view of our overall system architecture as a diagram. This way, we can treat agents as reusable tools for composition and testability.
Try it in 2 minutes
Pick your path and go! If you'd like to use Langflow without any command line work, feel free to download the desktop app and take it for a spin!
If you'd like to try it with uvx, a command-line tool that creates ephemeral Python environments on demand, you can run this from your command line:
uvx langflow run
Or with Docker:
docker run --rm -p 7860:7860 langflow-ai/langflow
Then open http://localhost:7860 and build the flow. You can either start by dragging and dropping this JSON file into your project, or by manually building the flow yourself. Either way, the flow will end up looking something like this:
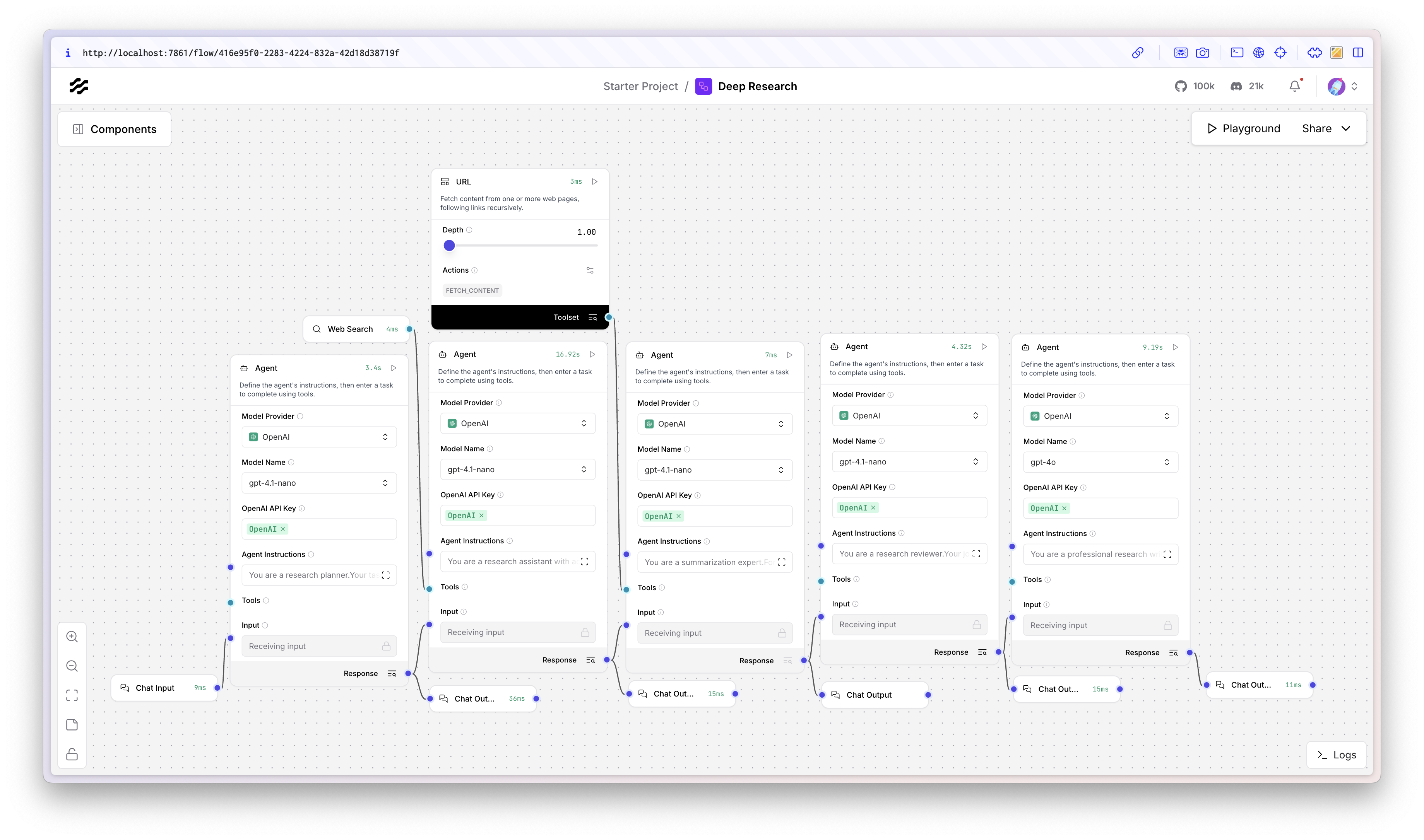
To manually build the flow, follow these steps:
- Add a
Chat Input - Add 5 agents and fill in your API keys
- Give your agents the right tools:
- The research agent gets the Web Search tool to find the right sources, and
- The summarizer agent gets the URL component as a tool to read the contents of sources and summarize them. Be sure to turn "tool mode" to on on the URL component.
- Construct the right system prompts for each agent (more on this below)
- Wire it all together, adding
Chat Outputcomponents as necessary
System Prompts
Here are the system prompts we used for each agent:
Planner
You are a research planner. Your task is to break down the user’s question into 2 to 4 sub-questions that, together, cover the topic. Instructions: - Analyze the user’s input. - Identify the core dimensions or unknowns. - Write 3 to 7 clear, self-contained sub-questions. Respond in this format (use markdown): ```markdown **Main Question:** <restate the question> **Subquestions:** 1. ... 2. ... 3. ... ```
Source Finder
You are a research assistant with access to search tools. For each sub-question below, find the most relevant source (use entire sub-question or a smaller search term for each). For each source, extract: - title - url - a short summary of relevance - the full content (or a placeholder if not available) Respond in this format (use markdown): ```markdown ### Subquestion: ... **Sources:** 1. **Title:** ... - **URL:** ... - **Summary:** ... - **Content:** ... 2. ... ```
Summarization Expert
You are a summarization expert. For each sub-question and its associated sources, extract the most important information. Instructions: - Focus only on content relevant to the sub-question. - Summarize each source in 2–4 concise bullet points. Respond in this format (use markdown): ```markdown ### Subquestion: ... **Summaries:** - **Source:** ... - ... - ... - ... - **Source:** ... - ... ```
Reviewer
You are a research reviewer. Your job is to analyze the current coverage of all sub-questions and identify any missing information. Instructions: - For each sub-question, evaluate whether the summaries fully answer it. - Identify gaps or missing angles. - Propose new sub-questions only if needed. Respond in this format (use markdown): ```markdown **Gaps:** - ... **New Subquestions:** 1. ... ```
Research Writer
You are a professional research writer. Your task is to synthesize a structured report that fully answers the main question using the summaries provided. Instructions: - Group findings by sub-question or theme. - Present a clear, well-organized explanation. - Be concise and include citations. Respond in this format: ## Final Report Title <final report text>
Of course, this is your multi-agent system, so feel free to tweak these prompts as needed to best suit your use case.
Best Practices
To further refine your flow, here are some tips that have served us and myriad other developers in practice:
-
Keep outputs structured: given that we have many agents that talk to each other, it's critical that we do not end up with a game of broken telephone. A great way to mitigate against this is to work with data as structured as possible, even working with JSON/DataFrames if/where you can.
-
Prefer compact bullets: since humans read only the final report, it would help to optimize the intermediary data for machines. If we're already working with structured data, we may as well also keep that data as terse as possible.
-
Parallelize where possible: in our example case here, each agent depends on the one before it. In some cases, you may be able to run a set of agents in parallel to reduce latency and serve users as fast as possible. Operating with a latency-sensitive mindset is highly favorable with multi-agent systems.
Make it yours
Now that we've got a starter multi-agent system, we are now empowered to fine-tune it to meet our specific needs: we can swap providers per node (OpenAI, Anthropic, etc.) or use local open-source models for scaffolding, saving the heavy model for final report synthesis. We could also add a Citations node to compile references with titles and permalinks. The possibilities are endless and we'd love to hear from you!
If you're taking this for a spin, please stay in touch with us on X at @langflow_ai, and join the Discord. Ship your first deep‑research agent, share a screenshot, and tag us. We can’t wait to see what you build.
Frequently Asked Questions
Here are a list of answers to questions we often get when talking about Langflow and Multi-Agent systems. If you find something unanswered here, please do ask us on Discord and/or X.
What is a Multi‑Agent System (MAS)?
A MAS is a workflow where several narrow, specialized agents collaborate toward a goal. Each agent owns a single responsibility (plan, retrieve, summarize, review, synthesize), exposes a clear input/output contract, and may have its own tools and model. The power comes from composition, not from any one agent being “smart at everything.”
When should I use a MAS?
Use a MAS when the problem decomposes naturally into stages with distinct competencies; when you want fault isolation and the ability to test/tune components independently; when you need different tools or models at different steps; when auditability and reproducibility matter (clear artifacts at each stage); or when you expect to iterate and scale parts of the pipeline differently.
When should I not use a MAS?
Avoid MAS for simple, single‑shot tasks where one prompt suffices; for ultra‑low‑latency user interactions where orchestration overhead dominates; when you cannot define clean interfaces between steps; or when you have severe token/cost constraints that make intermediate artifacts impractical.
How many agents do I need?
Start with the fewest that cover distinct responsibilities—often three to five. Add agents only when there is a clear conflict of concerns (e.g., retrieval vs. synthesis) or measurable quality/maintainability gains. Measure latency and cost as you scale; prefer merging stages over micro‑agents if complexity creeps up without benefits.
Can agents run in parallel?
Yes, when their work is independent. Examples: fetching sources for multiple sub‑questions, or summarizing a set of documents is naturally parallel (map → reduce). In Langflow, branch where possible and use the loop node judiciously. Keep outputs deterministic, cap concurrency to respect provider rate limits, and make retries idempotent.
Common pitfalls (and how to avoid them)
Too many tools per agent causing analysis paralysis; unstructured outputs that break downstream parsing; prompt drift across versions; missing timeouts/retries on network tools; hidden shared state between agents; and cost creep from running large models too early. Fix by keeping outputs structured, limiting toolsets per agent, versioning prompts/flows, adding sensible timeouts/backoff, isolating state, and reserving bigger models for the final synthesis.
Do I need API keys to try this?
Not for Langflow, but only for your AI model providers of choice: you will need an API key for OpenAI, Anthropic, etc. For Langflow, you can explore Langflow with the Desktop app or by running locally.
Can I use local, open‑source models (no cloud)?
Yes. You can connect to local, OpenAI‑compatible servers or other OSS runtimes and run the entire pipeline offline (just avoid web‑search tools). This is great for privacy, prototyping, and cost control.
What’s the fastest way to get started?
Use the Desktop app to skip the CLI entirely, or run locally and open http://localhost:7860. The “Try it in 2 minutes” section above has both uvx and Docker options.
How much will this cost me?
Langflow is open‑source. Your cost comes from whatever models and tools you call. Keep small models for planning/retrieval and reserve large models for the final writer to minimize spend.
How do I version and share flows with my team?
Export your flow to JSON and check it into Git. Teammates can import the same JSON to reproduce your graph, prompts, and wiring. Keep secrets in environment variables or your local key manager, not in the JSON.
How do I debug a flaky node?
Run nodes step‑by‑step, inspect inputs/outputs, and add temporary Chat Output taps to visualize intermediates. Constrain outputs with simple schemas (lists/objects) so failures are obvious and downstream parsing stays trivial.
Can agents call other agents?
Yes. Treat agents as reusable tools. Use sub‑flows for common patterns (e.g., retrieval + summarization) and compose them where needed.
Can I mix different models in one flow?
Absolutely. Model mixing per node is a first‑class pattern: lean models for structure and search, a beefier model only where it improves the final synthesis.
How do I deploy this to production?
Containerize it (see the Docker example above), configure environment variables for secrets, and place it behind your existing reverse proxy. For teams, run it on your preferred orchestrator and persist flow JSON alongside application code. We also have a full blog post about this that may be worth a read.
Does Langflow send my data anywhere by default?
No. Running locally keeps data on your machine unless you explicitly add tools that make network calls. Review each tool’s permissions and outputs.
How can I contribute or request features?
Start a discussion in the Discord, share a minimal flow JSON that reproduces your idea, and tag us on X with context. Community flows and clear reproductions get the fastest feedback.


