
💡 This blog post was also published as a video for those that prefer visual media.
Remember when choosing an LLM was simple? Yeah, neither do we. Recently, there have been a lot of options to choose from: o3, o1, 4o, 4o-mini, GPT-5, Claude Opus, Gemini... the list goes on. Each model has its sweet spot: some excel at reasoning, others at speed, and a few at cost-efficiency. But here's the kicker: most users don't care about a zoo of models and often just want the best possible answers to their queries.

OpenAI's GPT-5 interface elegantly solves this with intelligent model routing, automatically selecting the right model for each query. It behaves like a load balancer both for intelligence and model-specific traffic: simple queries get fast, cheap models while queries that require complex reasoning bring out the big guns.
Today, we're building this exact pattern in Langflow. No black boxes, just clean and observable routing logic you control.
The Architecture: Agents All the Way Down
Here's our game plan: we'll create a multi-agent system (MAS) where a "judge" agent evaluates incoming queries and routes them to specialized downstream agents. It's simpler than it sounds and is quite effective.
User Query → Judge Agent → Router → Specialized Agent → Response ↓ ↓ "default" 4o-mini "think" GPT-5/o3
The beauty of Langflow here is that each component is swappable: if you don't like OpenAI, you can freely swap in Claude at any time without much ceremony. If you need custom routing logic, you can edit the judge's prompt. Throughout this tutorial, it should become clear that this is a pattern that you can adapt to your specific needs.
Implementation
We'll start by firing up Langflow. The easiest way to do this is to download and run Langflow Desktop. If you prefer the terminal, you can run uvx langflow run provided you have uv installed. Once Langflow is running, we'll go ahead and open it up at http://localhost:7860. There, we'll create a new blank flow and drag in a Chat Input component to get started. Be sure to have any API keys handy for any models you intend to use. For this flow, we use exclusively OpenAI but you can freely choose and customize according to your preference.
💡 This flow can be downloaded as JSON right here. You can drop it right into Langflow and start experimenting immediately.
When you're finished, your flow will look something like the image below. We will spend the next few sections exploring each part of this flow in detail.
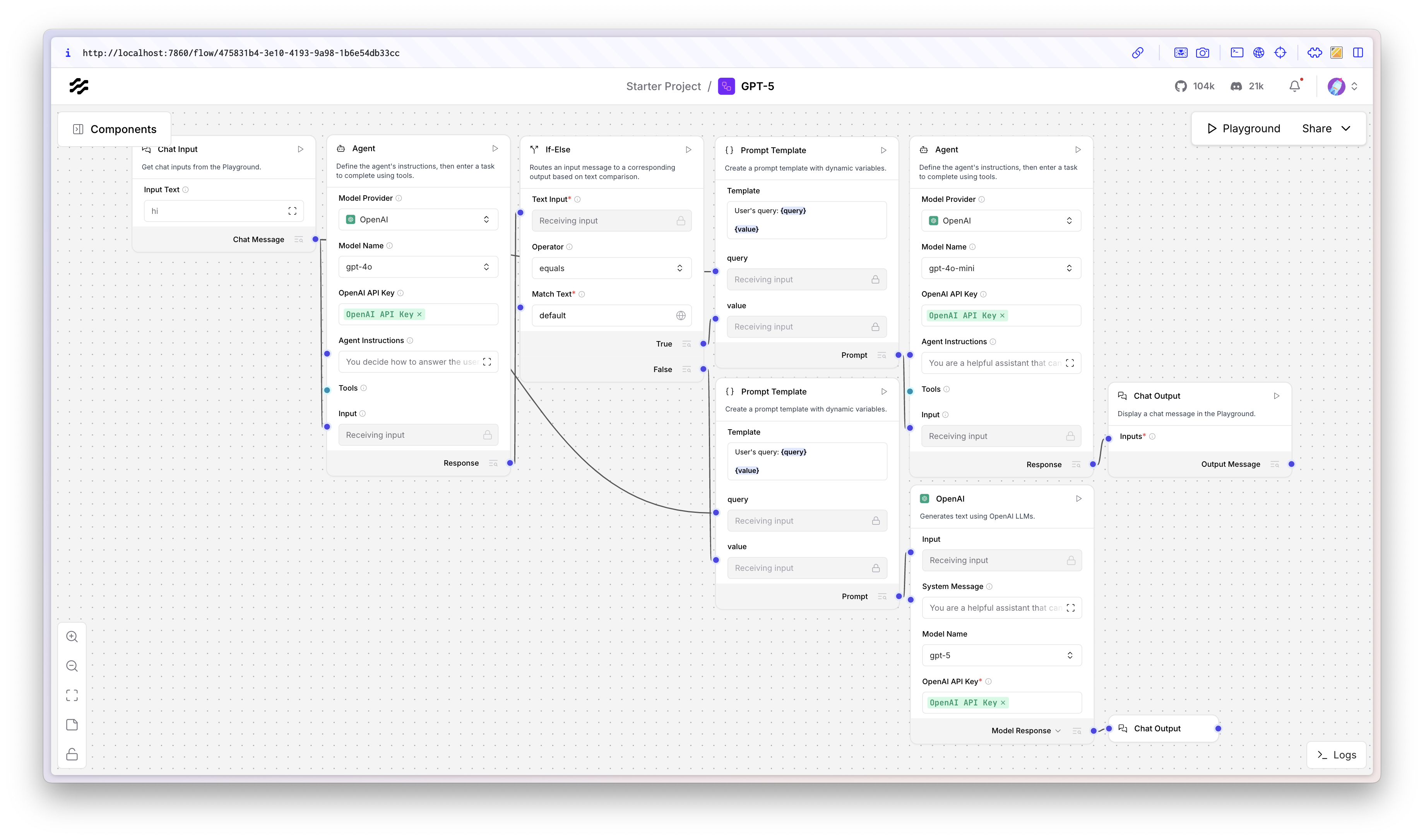
Step 1: The Judge Agent
Now that we're receiving input from a user, we'll need somewhere for it to go so let's drop in an Agent component. This is our traffic controller, the brains of the operation. Its system prompt is rather simple:
You decide how to answer the user. If you need to think more about their query, respond with one word only: think If it's an easy query, respond with one word only: default
That's it. No complex scoring algorithms, no ML models, just good old-fashioned context engineering. We're using GPT-4o here because routing decisions need to be smart but don't require deep reasoning. 4o has strong system prompt adherence compared to its mini counterpart.
You'll need to fill in the system prompt and an API key here, pipe the Chat Input into the right field, and we should be good to go.
Step 2: Conditional Routing
Here's where Langflow shines. Instead of writing custom routing code, we use the built-in If/Else component. It's a primitive that composes beautifully into more complex AI workflows. We'll use it like so:
- Input: Agent's response
- Condition:
equals "default" - True branch: Route to 4o-mini
- False branch: Route to GPT-5/o3
This visual programming approach means you can trace every decision path and optimize for cost-efficiency: run more expensive models for more complex queries and save costs on simpler queries. We're starting to already see value here. Let's press on.
Step 3: Prompt Templates
Both branches need context. We'll drag in some Prompt Template components that inject:
- The original user query
- The routing decision (for logging/debugging)
To do that, this will be the content of our Prompt Template components:
User's query: {query} Routing decision: {judge_value}
Pro tip: Keep these templates minimal. The more you add here, the more tokens you burn on every request. Save the elaborate system prompts for your specialized agents.
Step 4: The Specialist Agents
Now for the fun part—configuring our specialized agents. Let's start with two: one for complex reasoning, and one for quicker queries.
| Factor | Complex Reasoning | Quicker Queries |
|---|---|---|
| Cost | $1.250/1M tokens (input) and $10/1M tokens (output). More than 10x on output tokens compared to the cost of the faster agent. | $0.20/1M tokens (input) and $0.80/1M tokens (output) |
| Latency | >30 seconds | Sub-second |
| Example Prompt | "Explain quantum mechanics to a 2-year-old" | "What's the capital of France?" |
In Langflow, components are just Python code. If an LLM component has models missing from its dropdown, we can just go into the code and add them as Phil writes in another blog post. We'll do this to get GPT-5 into Langflow for now though this will change with an upcoming update.
Be sure to drop your API keys into each model and pipe in your prompt templates. From here, there's not much left to do!
Step 5: Putting it all together
To wrap this up, we will connect chat outputs to both agents. That's it! From here, we've got our working routing system ready for use. We can test this out by going to the Playground in Langflow and typing in some prompts: some that require reasoning and some that don't to test the system.
Some examples of prompts we can test:
- "What's the capital of France?" (should use the faster model)
- "Explain the plot of the Iliad but in French to a Japanese child in Kyoto" (should use the reasoning model).
These example prompts may be somewhat contrived, but they should give us a good idea of how the system is working or is expected to work. We'd love to hear what prompts you use to test the system and your success/failure rates so if you do give this a try, please share them with us on X or Discord.
Next Steps and Inspiration
Why stop there? Now that we've got a working routing system, we can start to think about how we can improve it. Here are some ideas.
Context Engineering
You could enhance your judge with context about the user, the conversation history, and even server load to optimize for efficiency of the overall system with this type of system prompt:
Previous conversation turns: {history} User subscription tier: {tier} Current API rate limits: {limits} Time of day: {time} User's query: {query} Choose the right model based on the context and the user's tier: free tier users should get the cheaper model after 5 conversation turns. If the user is a paid tier user, they should get the more expensive model unless their query is extremely simple.
This way, your judge even becomes a natural rate limiter that routes more traffic to cheaper models depending on the context: the user's tier, server load, rate limits, and more.
Further, since everything's observable as more or less a diagram in Langflow, you can run experiments:
- Test different routing criteria.
- Compare model performance on real queries.
- Gradually roll out new models.
The Bigger Picture
This pattern isn't just about saving money—it's about building intelligent and antifragile systems. When GPT-6 drops next month (we can dream), you wouldn't have to rewrite your application but instead update one routing rule. If a hyperscaler has an outage, your system gracefully degrades to cheaper models based on the intelligent Judge Agent.
This pattern lends itself well to fault tolerance, resilience, and pleasant user experience. Happy building!
Frequently Asked Questions
What is smart model routing and why should I care?
Smart model routing automatically selects the optimal LLM for each query based on complexity, cost, and performance requirements. Instead of using GPT-4 for everything (expensive!) or GPT-3.5 for everything (sometimes inadequate!), you dynamically route each request to the right model. With Langflow's visual approach, you can implement this in minutes, not days, and see exactly how your routing logic works.
How is this different from just calling different models manually?
Manual model selection puts the burden on your users or your code to decide which model to use. Smart routing makes this decision automatically using an intelligent judge agent. Langflow makes this pattern visual and debuggable—you can literally watch your queries flow through the routing logic in real-time, something impossible with traditional code-based approaches.
How does the judge agent decide which route to take?
The judge agent uses a lightweight-but-capable LLM (like GPT-4o) with a focused prompt to evaluate query complexity. The beautiful part about Langflow is you can see and modify this decision logic instantly. Don't like how it's routing? Click on the judge agent, edit the prompt, and watch the changes take effect immediately. No redeployment, no code changes, just instant iteration.
What if the judge agent makes a wrong routing decision?
Langflow's visual debugging makes this a non-issue. You can:
- See exactly which path each query takes
- Add logging components anywhere in the flow
- Test individual components in isolation
- A/B test different routing strategies in parallel
- Add override rules for specific query patterns
Traditional code-based systems hide these decisions in logs. Langflow makes them visible and fixable in real-time.
Can I use models from different providers?
You can mix OpenAI, Anthropic, Google, Cohere, and even local models in the same flow. Want GPT-4 as your judge, Claude for complex reasoning, and Llama for simple queries? Just drag in the components and connect them.
Will this add latency to my application?
The judge agent adds 200-300ms of latency, but simple queries then route to fast models that respond in under 500ms total. Complex queries that need reasoning models would have taken 2-5 seconds anyway. Langflow's parallel processing capabilities let you warm up both paths simultaneously and cancel the unused one, effectively hiding the routing latency.
Why is Langflow better than coding this myself?
- Visual Debugging: See exactly where each query goes and why
- Instant Modifications: Change routing logic without redeploying
- Component Reusability: Share judge agents across multiple flows
- Version Control: Roll back routing changes instantly
- Team Collaboration: Non-technical team members can understand and modify flows
Can I version control my Langflow routing system?
Yes! Langflow flows are JSON files that work perfectly with Git. Within Langflow, you can also duplicate flows and save alternate versions of them that your applications can consume. This way, you can run A/B tests, and instantly rollback bad routing decisions. You get both developer-friendly Git integration and user-friendly primitives for alternative version flows.
How do I integrate this with my existing application?
Langflow provides an out-of-the-box API that can be called by any client.
Can I route based on factors other than query complexity?
Langflow makes multi-factor routing simple:
- User tier: Premium users get better models
- Time of day: Use cheaper models during off-peak
- Query history: Learn from previous routings
- Current load: Dynamically adjust based on system load
- Cost budget: Enforce spending limits in real-time
- Geographic location: Route to region-specific models
Just add these factors to your judge agent's context or create multiple routing stages.
How long does it take to implement smart routing?
With Langflow's templates: literally 5 minutes to a working prototype. Our GPU-5 routing template includes:
- Pre-configured judge agent
- Optimized routing logic
- Example prompts for both paths
- Cost tracking components
- Basic monitoring setup
Just add your API keys and customize the prompts.
Do I need to be a developer to use Langflow?
No! That's the beauty of visual programming. Product managers, data scientists, and even interns have built sophisticated routing systems with Langflow. If you can draw a flowchart, you can build AI routing. And when you do need code, every component is editable by developers on your team.


