
One of the challenges in building retrieval-augmented generation (RAG) powered AI agents is getting clean, accurate data out of messy documents like PDFs. In Langflow 1.6 the File component was upgraded to use Docling to simplify document parsing and produce quality output.
In this post we'll look at how you can use Langflow and Docling to convert PDFs to Markdown and discuss how you can use this in your AI applications.
What is Docling?
Docling is an open-source document processor that's built for parsing diverse file formats and producing clean content for generative AI. It supports ingestion of files from PDFs and DOCXs to image files. It is capable of understanding text in PDFs and images through optical character recognition (OCR) and techniques like understanding page layout and reading order, or via a vision language model (VLM).
Docling was introduced to Langflow in version 1.5 and then it was further integrated in version 1.6 powering the advanced parser in the File component. This means that all the power of Docling is available in Langflow out of the box.
Let's take a look at how to work with Docling in Langflow and what it can do.
Parsing PDFs with Docling in Langflow
This might be the simplest flow you'll ever see in Langflow, but it's deceptively powerful. Open up Langflow, create a new blank flow and drag two components onto the canvas:
- A File component
- A Chat Output component
Connect the File component's Raw Content output to the Chat Output component's input.
If you'd prefer to download the flow and import it instead, you can find the flow JSON in this GitHub repo.
Select a PDF to test with, if you don't have one to hand, you could use this paper on Docling.
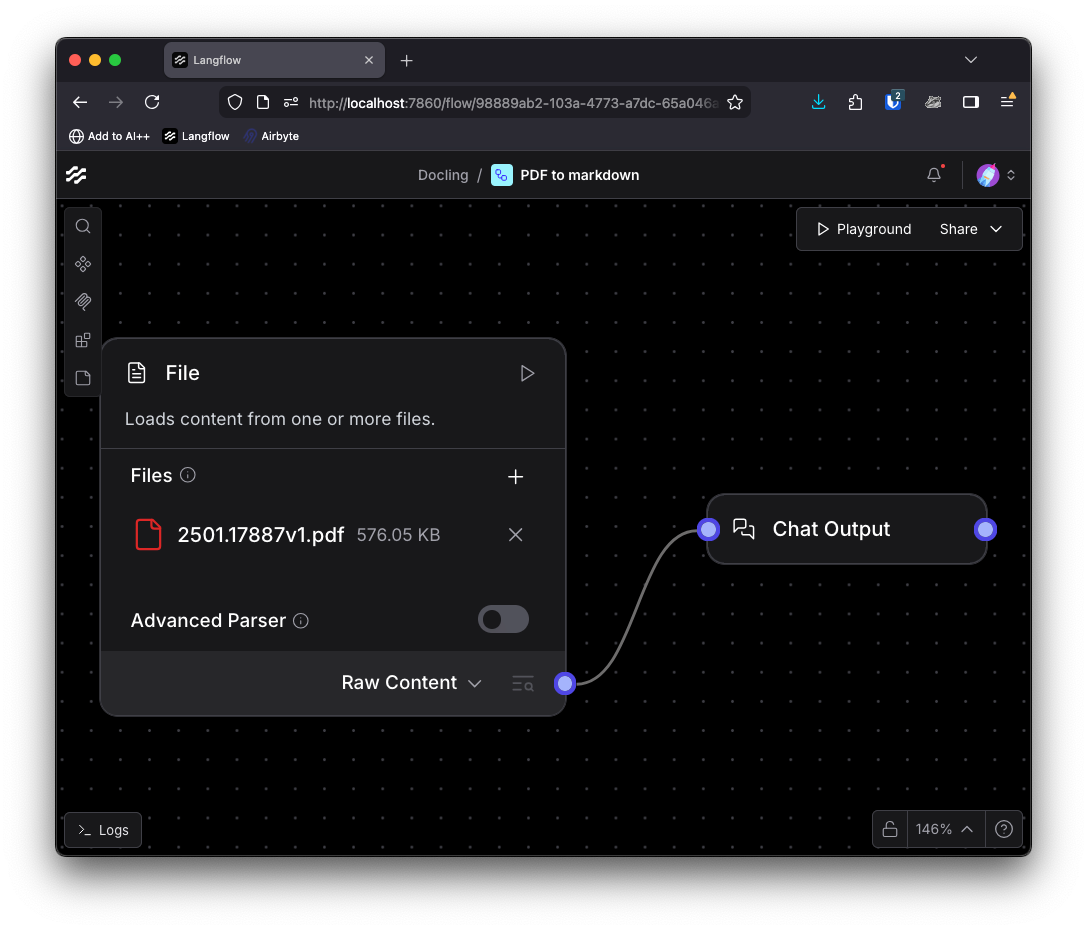
Open the Playground and click the Run Flow button. This will parse the document with Langflow's basic PDF parser. The result is OK. The text is mostly in the right reading order, occasionally interrupted by a footnote or image caption. You will notice that there is very little structure in the output; headings and paragraphs run into each other and it's mostly just a stream of text.
Return to the flow and toggle the advanced parser. More options become available:
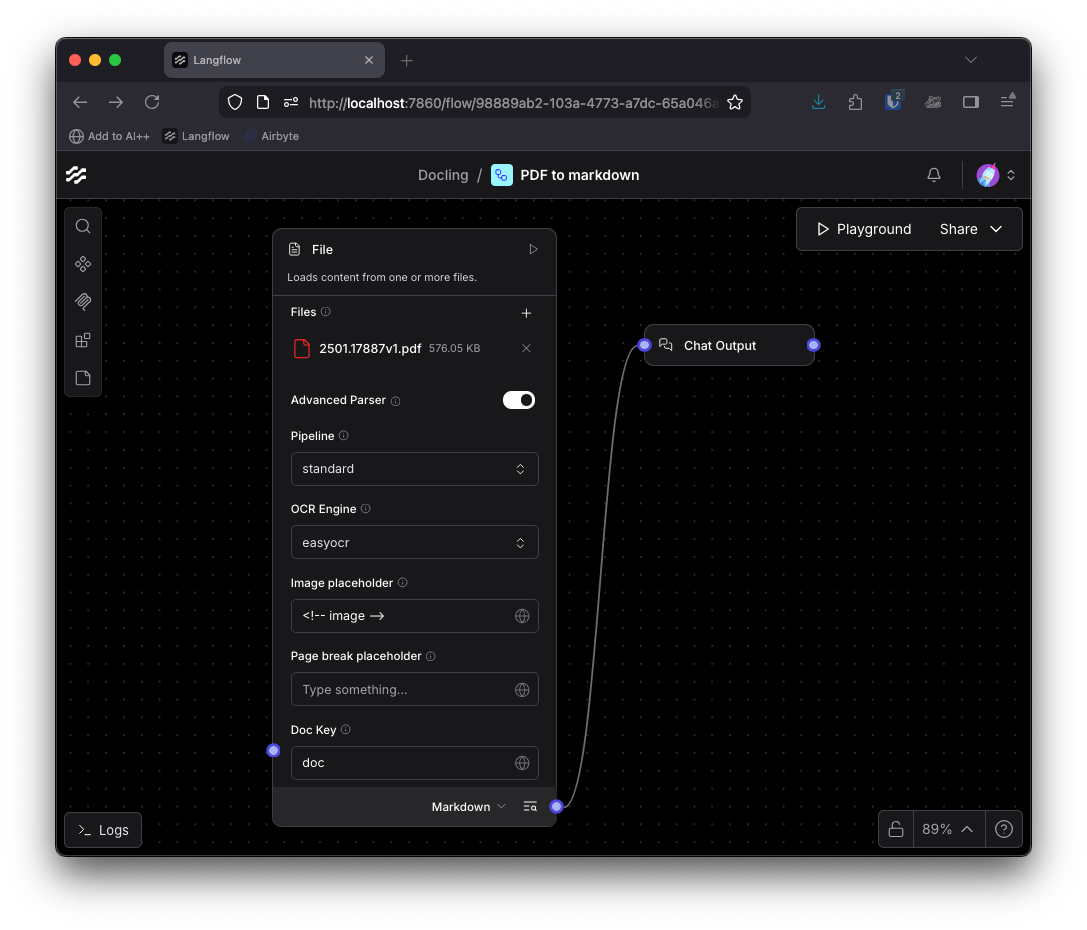
You can either choose to use the standard Docling pipeline, which applies a sequence of AI models to extract content and understand the layout. You can also opt to add the EasyOCR engine for optical character recognition as part of the pipeline.
Or you can choose the vlm pipeline. This is a simpler pipeline that uses the Granite-Docling-258M vision language model to parse and process the document in one shot.
You will need to reconnect the File component output to the Chat Output; select Markdown as the output and connect directly to the output component.
You can now try the options out by selecting them, opening the Playground and running the flow. Docling attempts to retain the structure of the document and you can see this with various headers and other structure within the markdown output.
What can you do with this?
Converting a PDF to markdown is just the first step. You could use this to pass the contents of a document to a language model and summarize the content or chat with the PDF.
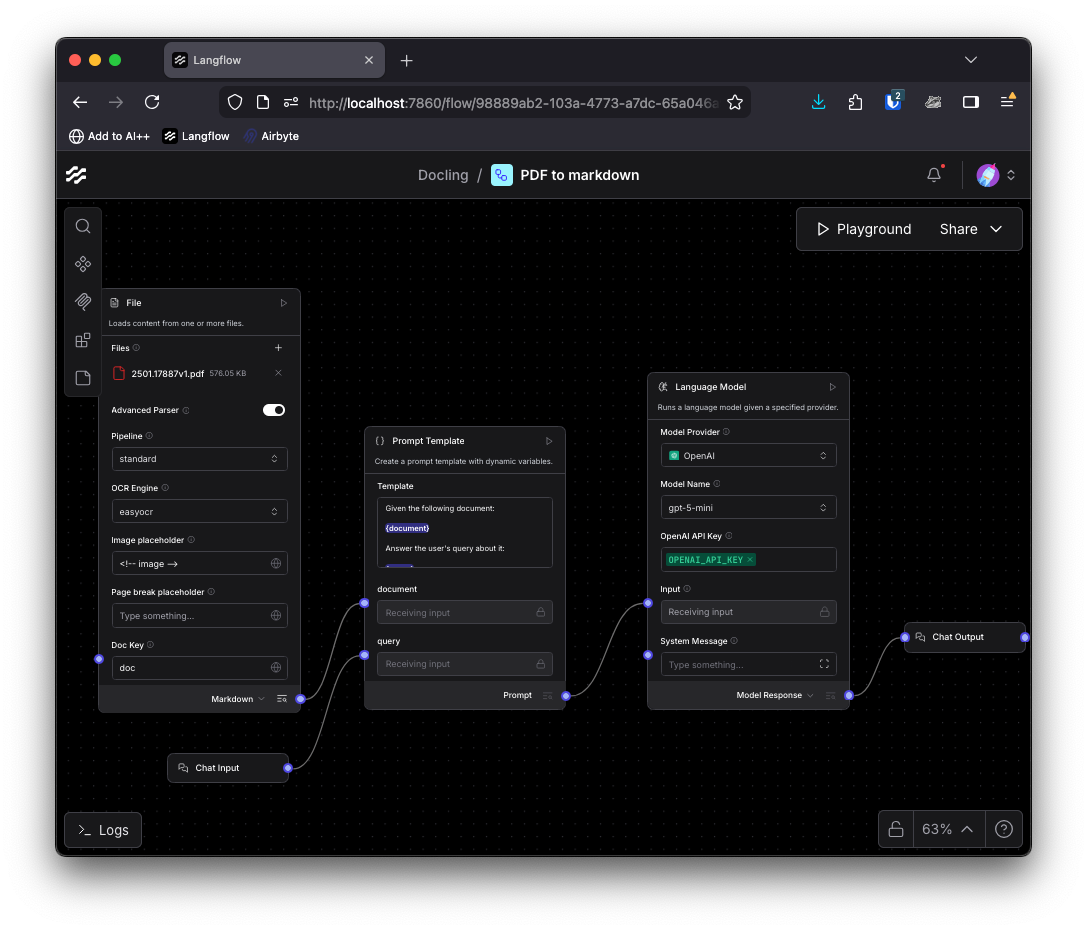
You could turn the markdown output into data using a Type Convert component and then split it into chunks based on the markdown structure with the LangChain Language Recursive Text Splitter, then embed the chunks and store them in a vector database as a retrieval-augmented generation (RAG) ingestion pipeline.
Or you can build it into an application that makes it easier to see the markdown output. I had Bob put together an interface to connect with my Langflow flow using Next.js and the JavaScript Langflow client. You can find the project on GitHub and use it to try out the different pipeline options.
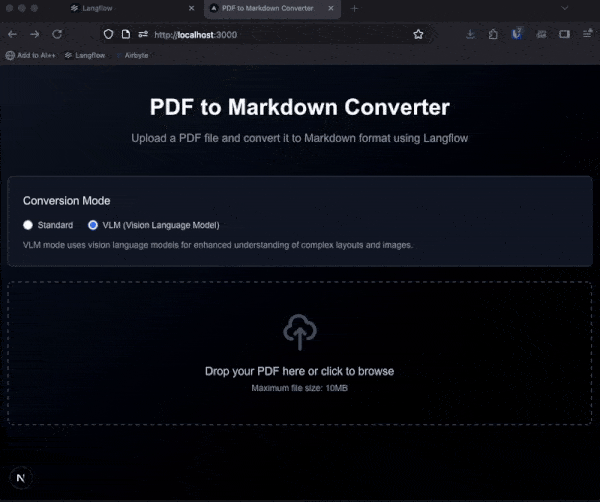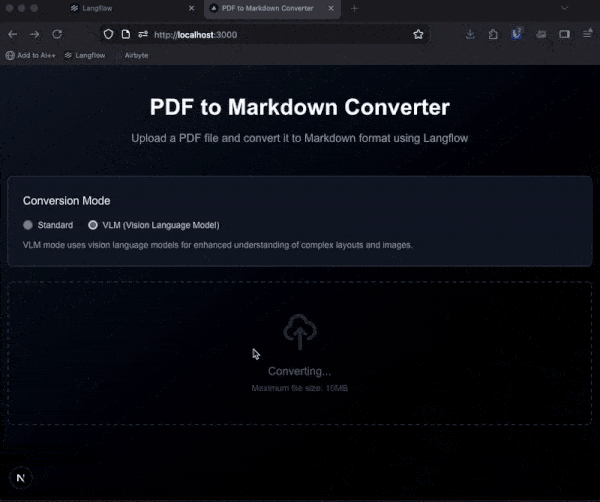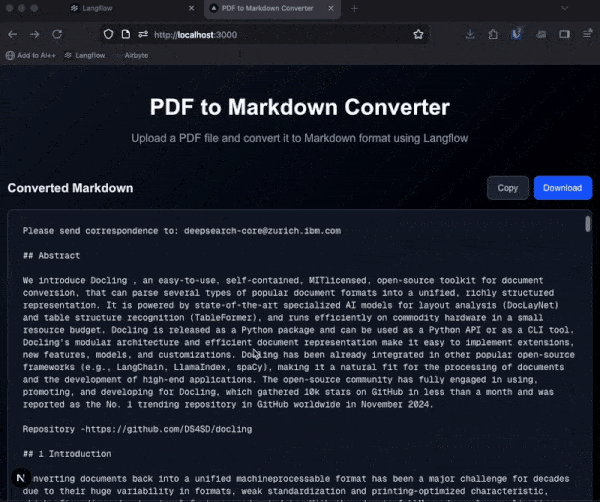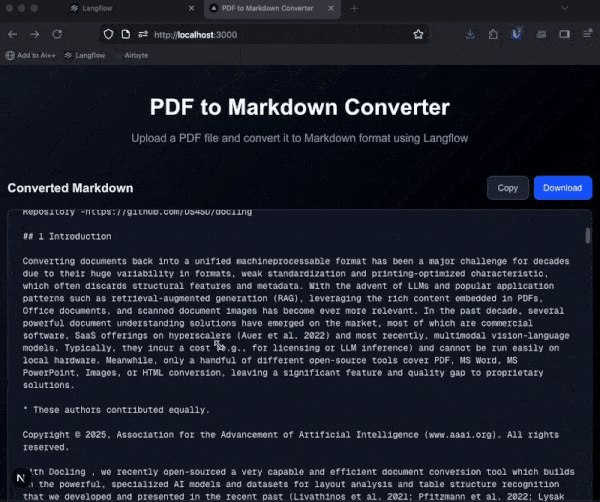
When handling files with Langflow via the API, you need to upload them first, then provide the uploaded file path to the flow as a tweak to the file component.
The code for integrating Langflow into the application boils down to the following, where file and mode have been provided from the form data from an incoming HTTP request.
import { LangflowClient } from "@datastax/langflow-client";
const client = new LangflowClient({
baseUrl: process.env.LANGFLOW_BASE_URL,
apiKey: process.env.LANGFLOW_API_TOKEN,
});
const flow = client.flow(process.env.LANGFLOW_FLOW_ID);
// Step 1: Upload the file to Langflow
const uploadResponse = await client.files.upload(file);
// Step 2: Run the flow with the uploaded file path and pipeline mode as tweaks
const fileComponentName = process.env.LANGFLOW_FILE_COMPONENT_NAME;
const response = await flow
.tweak(fileComponentName, {
path: uploadResponse.path,
pipeline: mode,
})
.run("");
The above code will execute your flow from any TypeScript or JavaScript-based app, uploading a document from the user and immediately passing it to the flow. This can be used in a variety of contexts depending on your use case.
Leave the PDF parsing to Docling
In this post you've seen a number of ways you can combine Docling and Langflow to parse PDFs and turn them into markdown, text chunks for a RAG system, or an interactive chat.
Using this flow you can experiment with the different parsing options for documents in Langflow and with this application you can explore using them, as well as how you would integrate Langflow into an application.
We'd love to hear how you're using Docling to improve file ingestion in your AI applications. Drop us a message on Twitter, on LinkedIn, or join the Discord.
FAQ: Converting PDFs to Markdown with Docling and Langflow
What is Docling and how does it help with PDFs?
Docling is an open-source document processor designed to parse diverse file formats, including PDFs, DOCXs, and images. It uses OCR and AI models to extract clean, structured content, making it ideal for preparing documents for generative AI applications.
How is Docling integrated into Langflow?
Docling powers the advanced parser in Langflow’s File component. This allows users to easily parse documents and extract high-quality content directly within Langflow.
What are the steps to convert a PDF to Markdown in Langflow?
Create a flow with a File component and a Chat Output component, select a PDF, enable the advanced parser and select the desired pipeline (standard or VLM). Select markdown in the output options and connect the File component to the Chat Output. Run the flow and you will see the markdown output in the Playground.
What can I do with the Markdown output from Docling?
You can use the Markdown output to summarize documents, chat with the PDF, or build a RAG (retrieval-augmented generation) ingestion pipeline by splitting and embedding the content for storage in a vector database.
How can I integrate Langflow and Docling into my own application?
You can use the Langflow API to upload files and run flows programmatically. Upload the file, then run the flow with the uploaded file path and desired pipeline as tweaks. This enables integration with web apps or other services.


